[スポンサードリンク]
ソフトの使い方
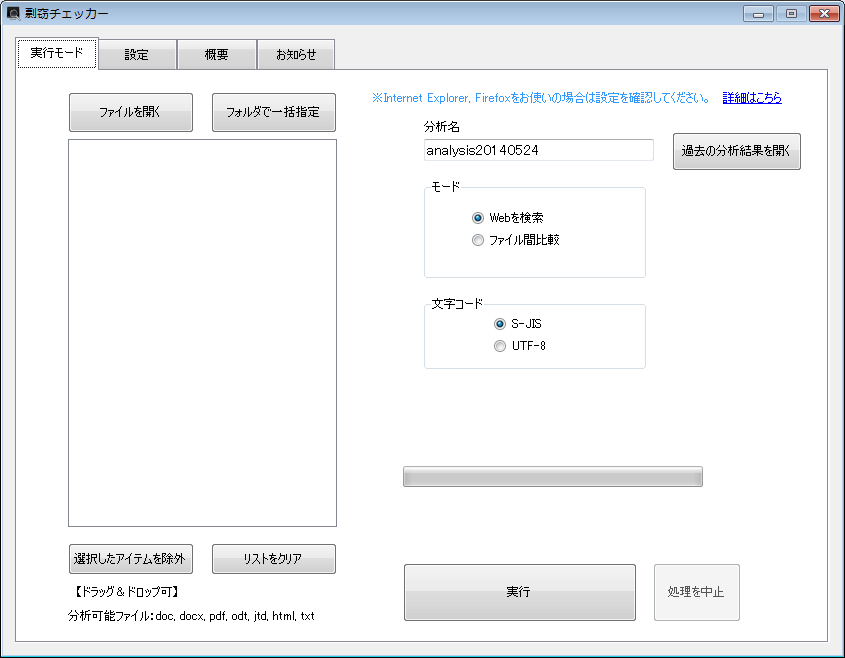
【実行モードのタブ】
(1)ファイルを選択
ボタンを押してから選択するか、リストボックスにドラッグ&ドロップでも読み込めます。
(2)モードの選択
(a) 「Webを検索」は対象文字列をインターネットで検索し、ヒット件数を示します。インターネットに接続している必要があります。処理には時間がかかります。
★入力:日本語など全角文字列を含む場合、80文字が最大入力です。英語など半角文字列のみの場合、30単語が上限です。「文字数が多すぎる」というメッセージが多い場合、区切りの指定を工夫してください。
(b) 「ファイル間比較」は、複数のファイルを対象に、文字列が重複していないかを調べます。比較的短時間で終わります。
(3)文字コードの選択
テキストファイル以外が対象の場合、デフォルトのままで問題ありませんが、テキストファイルを対象とする場合は文字コードに注意してください。また、同時に複数の文字コードを混ぜて分析することはできません。
(4)実行
分析には時間がかかる場合があります。気長にお待ちください。途中で分析をやめる場合は「処理を中止」のボタンを押してください。
(5)実行結果
次のような画面がでてきます。ご希望の操作を行ってください。
設定
(1)Web検索の設定
(a) 「汎用条件」では、X件以上あれば、一般的な表現として剽窃とは見なさない、という基準を設定します。
(b) 「最小文字列」は、検索タームの最小値を決めます。短すぎるとヒット件数が多くなり、正しい結果にならない場合があります。
(c) 「検出基準」は、剽窃が疑われるファイルであると判定する割合です。例えば、20%の設定だと、10文中2文以上が疑わしい場合、そのファイルを赤で表示します。
(d) 「分析用のテキストファイルを削除する」にチェックすると、Wordファイルを分析するために一時的に生成されたテキストファイル(txtフォルダ)を分析後に削除します。
(e) 検索エンジンはyahoo, livedoor, exciteを選択できます。yahooは連続使用をすると検索結果を取得できなくなることがあります。livedoor, exciteはyahooに比べて検索ヒット数が少なくなる傾向にあります。
(2)分割モード
文の分割基準を設定します。長すぎる文はヒットしにくく、短すぎる文はヒットが多くなります。ほどよい長さになるよう、この設定で調整してください。デフォルトでは句読点で区切ります。
ファイルから読み込む場合、「ファイルで指定」にチェックを入れ、「ファイルを開く」で指定してください。ファイルは、一行に1つ区切りとなる記号や文字列を入れます。
例えば:
===========
when
while
since
till
===========
とファイル中で指定すると、これらの文字列を区切りとして認識し、I was taking a bath when he gave me a call.という文は、「I was taking a bath」と「he gave me a call」に分割して検索されます。
(3)文章の整形
文章の部分的な修正による偽装を見抜くための機能です。例えば、「です。」「ます。」などを削除して検索・比較することができます。
ファイルで指定する場合、次のように書きます。
【置き換え】
===========
でした->だった
ありました->あった
===========
この設定で、「昨日は雨でした」という文は「昨日は雨だった」として検索されます。
【削除】
===========
でした->
ありました->
===========
削除をする場合は、->の後にスペースを入力してください。「昨日は雨でした」という文は「昨日は雨」として検索されます。
(a) 「汎用条件」では、X件以上あれば、一般的な表現として剽窃とは見なさない、という基準を設定します。
(b) 「最小文字列」は、検索タームの最小値を決めます。短すぎるとヒット件数が多くなり、正しい結果にならない場合があります。
(c) 「検出基準」は、剽窃が疑われるファイルであると判定する割合です。例えば、20%の設定だと、10文中2文以上が疑わしい場合、そのファイルを赤で表示します。
(d) 「分析用のテキストファイルを削除する」にチェックすると、Wordファイルを分析するために一時的に生成されたテキストファイル(txtフォルダ)を分析後に削除します。
(e) 検索エンジンはyahoo, livedoor, exciteを選択できます。yahooは連続使用をすると検索結果を取得できなくなることがあります。livedoor, exciteはyahooに比べて検索ヒット数が少なくなる傾向にあります。
(2)分割モード
文の分割基準を設定します。長すぎる文はヒットしにくく、短すぎる文はヒットが多くなります。ほどよい長さになるよう、この設定で調整してください。デフォルトでは句読点で区切ります。
ファイルから読み込む場合、「ファイルで指定」にチェックを入れ、「ファイルを開く」で指定してください。ファイルは、一行に1つ区切りとなる記号や文字列を入れます。
例えば:
===========
when
while
since
till
===========
とファイル中で指定すると、これらの文字列を区切りとして認識し、I was taking a bath when he gave me a call.という文は、「I was taking a bath」と「he gave me a call」に分割して検索されます。
(3)文章の整形
文章の部分的な修正による偽装を見抜くための機能です。例えば、「です。」「ます。」などを削除して検索・比較することができます。
ファイルで指定する場合、次のように書きます。
【置き換え】
===========
でした->だった
ありました->あった
===========
この設定で、「昨日は雨でした」という文は「昨日は雨だった」として検索されます。
【削除】
===========
でした->
ありました->
===========
削除をする場合は、->の後にスペースを入力してください。「昨日は雨でした」という文は「昨日は雨」として検索されます。